
ubuntu 安装使用Cgroups
Cgroups简介
Cgroups 是什么?
Cgroups 是 control groups 的缩写,是 Linux 内核提供的一种可以限制、记录、隔离进程组(process groups)所使用的物理资源(如:cpu,memory,IO 等等)的机制。最初由 google 的工程师提出,后来被整合进 Linux 内核。Cgroups 也是 LXC 为实现虚拟化所使用的资源管理手段,可以说没有 cgroups 就没有 LXC。
Cgroups 可以做什么?
Cgroups 最初的目标是为资源管理提供的一个统一的框架,既整合现有的 cpuset 等子系统,也为未来开发新的子系统提供接口。现在的 cgroups 适用于多种应用场景,从单个进程的资源控制,到实现操作系统层次的虚拟化(OS Level Virtualization)。
Cgroups 提供了一下功能:
- 限制进程组可以使用的资源数量(Resource limiting )。比如:memory 子系统可以为进程组设定一个 memory 使用上限,一旦进程组使用的内存达到限额再申请内存,就会出发 OOM(out of memory)。
- 进程组的优先级控制(Prioritization )。比如:可以使用 cpu 子系统为某个进程组分配特定 cpu share。
- 记录进程组使用的资源数量(Accounting )。比如:可以使用 cpuacct 子系统记录某个进程组使用的 cpu 时间
进程组隔离(Isolation)。比如:使用 ns 子系统可以使不同的进程组使用不同的 namespace,以达到隔离的目的,不同的进程组有各自的进程、网络、文件系统挂载空间。
进程组控制(Control)。比如:使用 freezer 子系统可以将进程组挂起和恢复。
Cgroups 相关概念及其关系
相关概念
任务(task)。在 cgroups 中,任务就是系统的一个进程。
控制族群(control group)。控制族群就是一组按照某种标准划分的进程。Cgroups 中的资源控制都是以控制族群为单位实现。一个进程可以加入到某个控制族群,也从一个进程组迁移到另一个控制族群。一个进程组的进程可以使用 cgroups 以控制族群为单位分配的资源,同时受到 cgroups 以控制族群为单位设定的限制。
层级(hierarchy)。控制族群可以组织成 hierarchical 的形式,既一颗控制族群树。控制族群树上的子节点控制族群是父节点控制族群的孩子,继承父控制族群的特定的属性。
子系统(subsytem)。一个子系统就是一个资源控制器,比如 cpu 子系统就是控制 cpu 时间分配的一个控制器。子系统必须附加(attach)到一个层级上才能起作用,一个子系统附加到某个层级以后,这个层级上的所有控制族群都受到这个子系统的控制。
相互关系
每次在系统中创建新层级时,该系统中的所有任务都是那个层级的默认 cgroup(我们称之为 root cgroup ,此 cgroup 在创建层级时自动创建,后面在该层级中创建的 cgroup 都是此 cgroup 的后代)的初始成员。
一个子系统最多只能附加到一个层级。
一个层级可以附加多个子系统
一个任务可以是多个 cgroup 的成员,但是这些 cgroup 必须在不同的层级。
系统中的进程(任务)创建子进程(任务)时,该子任务自动成为其父进程所在 cgroup 的成员。然后可根据需要将该子任务移动到不同的 cgroup 中,但开始时它总是继承其父任务的 cgroup。
图 1. CGroup 层级图
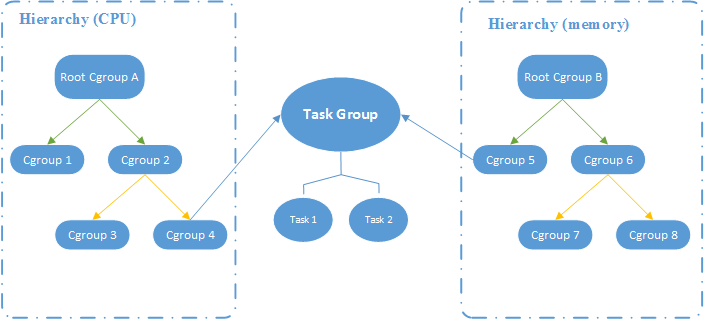
图 1 所示的 CGroup 层级关系显示,CPU 和 Memory 两个子系统有自己独立的层级系统,而又通过 Task Group 取得关联关系。
图 2. 进程与cgourps 关系示意图
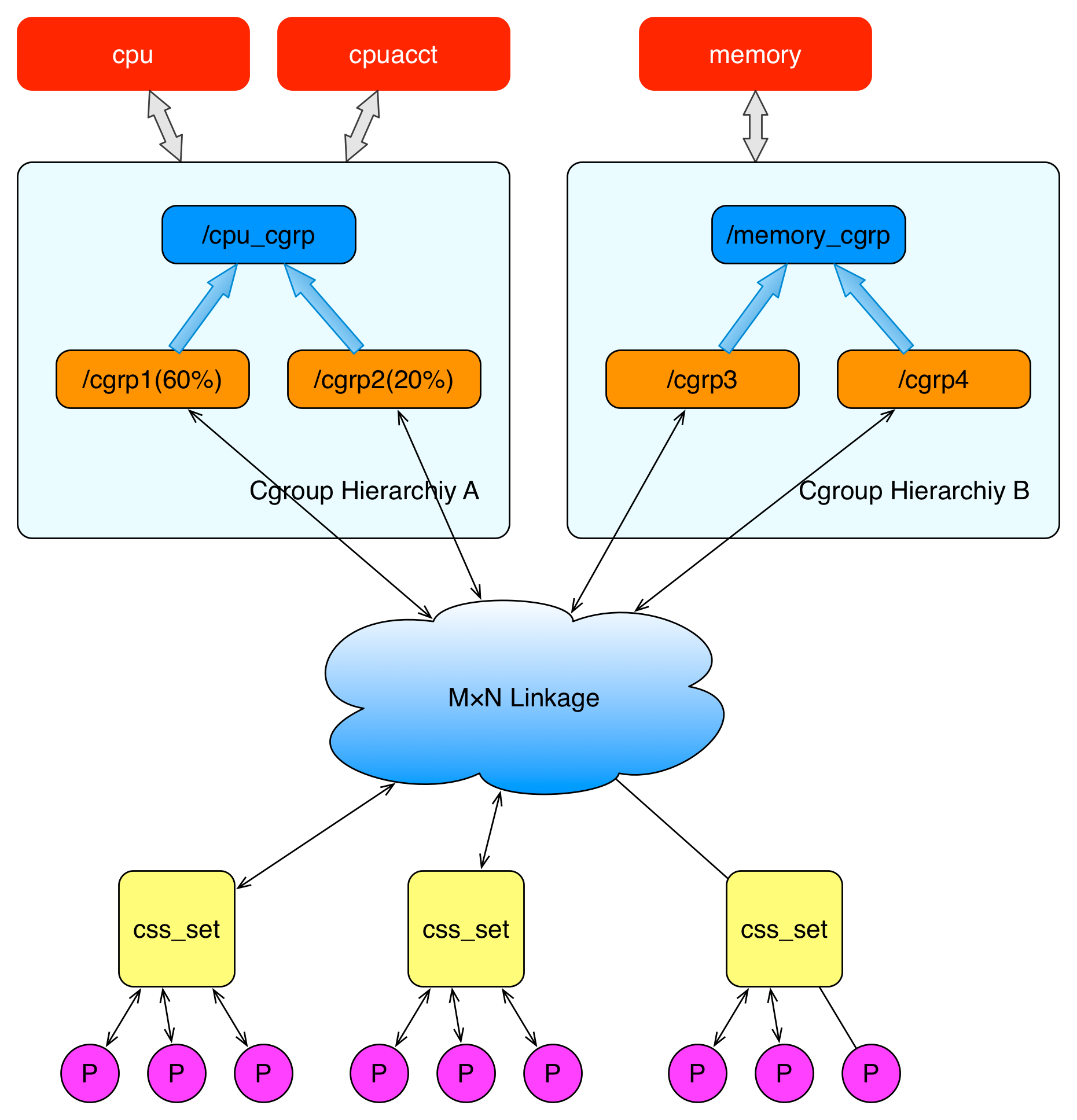
图2 从整体结构上描述了进程与 cgroups 之间的关系。最下面的P代表一个进程。每一个进程的描述符中有一个指针指向了一个辅助数据结构css_set(cgroups subsystem set)。 指向某一个css_set的进程会被加入到当前css_set的进程链表中。一个进程只能隶属于一个css_set,一个css_set可以包含多个进程,隶属于同一css_set的进程受到同一个css_set所关联的资源限制。
上图中的”M×N Linkage”说明的是css_set通过辅助数据结构可以与 cgroups 节点进行多对多的关联。但是 cgroups 的实现不允许css_set同时关联同一个cgroups层级结构下多个节点。 这是因为 cgroups 对同一种资源不允许有多个限制配置。
一个css_set关联多个 cgroups 层级结构的节点时,表明需要对当前css_set下的进程进行多种资源的控制。而一个 cgroups 节点关联多个css_set时,表明多个css_set下的进程列表受到同一份资源的相同限制。
Cgroups 子系统介绍
blkio – 这个子系统为块设备设定输入 / 输出限制,比如物理设备(磁盘,固态硬盘,USB 等等)。
cpu – 这个子系统使用调度程序提供对 CPU 的 cgroup 任务访问。
cpuacct – 这个子系统自动生成 cgroup 中任务所使用的 CPU 报告。
cpuset – 这个子系统为 cgroup 中的任务分配独立 CPU(在多核系统)和内存节点。
devices – 这个子系统可允许或者拒绝 cgroup 中的任务访问设备。
freezer – 这个子系统挂起或者恢复 cgroup 中的任务。
memory – 这个子系统设定 cgroup 中任务使用的内存限制,并自动生成由那些任务使用的内存资源报告。
net_cls – 这个子系统使用等级识别符(classid)标记网络数据包,可允许 Linux 流量控制程序(tc)识别从具体 cgroup 中生成的数据包。
ns – 名称空间子系统。
图3. CGroup 典型应用架构图
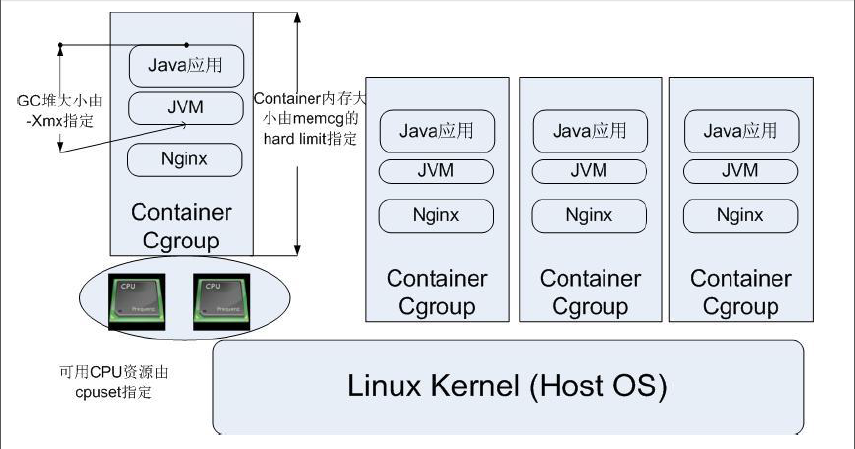
如图 2 所示,CGroup 技术可以被用来在操作系统底层限制物理资源,起到 Container 的作用。图中每一个 JVM 进程对应一个 Container Cgroup 层级,通过 CGroup 提供的各类子系统,可以对每一个 JVM 进程对应的线程级别进行物理限制,这些限制包括 CPU、内存等等许多种类的资源
Cgroups详解
cgroups 数据结构设计
我们从进程出发来剖析 cgroups 相关数据结构之间的关系。
在 Linux 中,管理进程的数据结构是 task_struct,其中与 cgroups 有关的:
|
其中 cgroups 指针指向了一个 css_set 结构,而 css_set 存储了与进程相关的 cgroups 信息。Cg_list 是一个嵌入的 list_head 结构,用于将连到同一个 css_set 的进程组织成一个链表。
下面我们来看 css_set 的结构:
struct css_set { |
其中 refcount 是该 css_set 的引用数,因为一个 css_set 可以被多个进程共用,只要这些进程的 cgroups 信息相同,比如:在所有已创建的层级里面都在同一个 cgroup 里的进程。
hlist 是嵌入的 hlist_node,用于把所有 css_set 组织成一个 hash 表,这样内核可以快速查找特定的 css_set。
tasks 指向所有连到此 css_set 的进程连成的链表。
cg_links 指向一个由 struct cg_cgroup_link 连成的链表。
Subsys 是一个指针数组,存储一组指向 cgroup_subsys_state 的指针。一个 cgroup_subsys_state 就是进程与一个特定子系统相关的信息。通过这个指针数组,进程就可以获得相应的 cgroups 控制信息了。
下面我们就来看 cgroup_subsys_state 的结构:
struct cgroup_subsys_state { |
cgroup 指针指向了一个 cgroup 结构,也就是进程属于的 cgroup。进程受到子系统的控制,实际上是通过加入到特定的 cgroup 实现的,因为 cgroup 在特定的层级上,而子系统又是附加到曾经上的。
通过以上三个结构,进程就可以和 cgroup 连接起来了:task_struct->css_set->cgroup_subsys_state->cgroup。
下面我们再来看 cgroup 的结构:
struct cgroup { |
sibling,children 和 parent 三个嵌入的 list_head 负责将同一层级的 cgroup 连接成一颗 cgroup 树。subsys 是一个指针数组,存储一组指向 cgroup_subsys_state 的指针。这组指针指向了此 cgroup 跟各个子系统相关的信息,这个跟 css_set 中的道理是一样的。
root 指向了一个 cgroupfs_root 的结构,就是 cgroup 所在的层级对应的结构体。这样以来,之前谈到的几个 cgroups 概念就全部联系起来了。
top_cgroup 指向了所在层级的根 cgroup,也就是创建层级时自动创建的那个 cgroup。
css_set 指向一个由 struct cg_cgroup_link 连成的链表,跟 css_set 中 cg_links 一样。
下面我们来分析一个 css_set 和 cgroup 之间的关系。
我们先看一下 cg_cgroup_link 的结构:
struct cg_cgroup_link { |
cgrp_link_list 连入到 cgroup->css_set 指向的链表,cgrp 则指向此 cg_cgroup_link 相关的 cgroup。
Cg_link_list 则连入到 css_set->cg_links 指向的链表, cg 则指向此 cg_cgroup_link 相关的 css_set。
那为什么要这样设计呢?
那是因为 cgroup 和 css_set 是一个多对多的关系,必须添加一个中间结构来将两者联系起来,这跟数据库模式设计是一个道理。cg_cgroup_link 中的 cgrp 和 cg 就是此结构体的联合主键,而 cgrp_link_list 和 cg_link_list 分别连入到 cgroup 和 css_set 相应的链表,使得能从 cgroup 或 css_set 都可以进行遍历查询。
那为什么 cgroup 和 css_set 是多对多的关系呢?
一个进程对应 css_set,一个 css_set 就存储了一组进程(应该有可能被几个进程共享,所以是一组)跟各个子系统相关的信息,但是这些信息有可能不是从一个 cgroup 那里获得的,因为一个进程可以同时属于几个 cgroup,只要这些 cgroup 不在同一个层级。
举个例子:我们创建一个层级 A,A 上面附加了 cpu 和 memory 两个子系统,进程 B 属于 A 的根 cgroup;然后我们再创建一个层级 C,C 上面附加了 ns 和 blkio 两个子系统,进程 B 同样属于 C 的根 cgroup;那么进程 B 对应的 cpu 和 memory 的信息是从 A 的根 cgroup 获得的,ns 和 blkio 信息则是从 C 的根 cgroup 获得的。因此,一个 css_set 存储的 cgroup_subsys_state 可以对应多个 cgroup。另一方面,cgroup 也存储了一组 cgroup_subsys_state,这一组 cgroup_subsys_state 则是 cgroup 从所在的层级附加的子系统获得的。一个 cgroup 中可以有多个进程,而这些进程的 css_set 不一定都相同,因为有些进程可能还加入了其他 cgroup。但是同一个 cgroup 中的进程与该 cgroup 关联的 cgroup_subsys_state 都受到该 cgroup 的管理(cgroups 中进程控制是以 cgroup 为单位的)的,所以一个 cgrouop 也可以对应多个 css_set。
那为什么要这样一个结构呢?
从前面的分析,我们可以看出从 task 到 cgroup 是很容易定位的,但是从 cgroup 获取此 cgroup 的所有的 task 就必须通过这个结构了。每个进程都会指向一个 css_set,而与这个 css_set 关联的所有进程都会链入到 css_set->tasks 链表. 而 cgroup 又通过一个中间结构 cg_cgroup_link 来寻找所有与之关联的所有 css_set,从而可以得到与 cgroup 关联的所有进程。
最后让我们看一下层级和子系统对应的结构体。层级对应的结构体是 cgroupfs_root:
struct cgroupfs_root { |
sb 指向该层级关联的文件系统超级块
subsys_bits 和 actual_subsys_bits 分别指向将要附加到层级的子系统和现在实际附加到层级的子系统,在子系统附加到层级时使用
hierarchy_id 是该层级唯一的 id
top_cgroup 指向该层级的根 cgroup
number_of_cgroups 记录该层级 cgroup 的个数
root_list 是一个嵌入的 list_head,用于将系统所有的层级连成链表
子系统对应的结构体是 cgroup_subsys:
struct cgroup_subsys { |
Cgroup_subsys 定义了一组操作,让各个子系统根据各自的需要去实现。这个相当于 C++ 中抽象基类,然后各个特定的子系统对应 cgroup_subsys 则是实现了相应操作的子类。
类似的思想还被用在了 cgroup_subsys_state 中,cgroup_subsys_state 并未定义控制信息,而只是定义了各个子系统都需要的共同信息,比如该 cgroup_subsys_state 从属的 cgroup。然后各个子系统再根据各自的需要去定义自己的进程控制信息结构体,最后在各自的结构体中将 cgroup_subsys_state 包含进去,这样通过 Linux 内核的 container_of 等宏就可以通过 cgroup_subsys_state 来获取相应的结构体。
从 cgroups 的数据结构设计,我们可以看出内核开发者的智慧,其中即包含了数据库模式设计来解决数据冗余问题,又包含了 OO 思想来解决通用操作的问题。
Cgroups安装
使用Ubuntu18.4环境
安装依赖程序sudo apt-get install cgroup-bin cgroup-lite cgroup-tools cgroupfs-mount libcgroup1
配置cgroups
新建 /etc/init/cgroup-lite.conf文件description "mount available cgroup filesystems"
author "Matos Iki <wx11055@163.com>"
start on mounted MOUNTPOINT=/sys/fs/cgroup
pre-start script
test -x /bin/cgroups-mount || { stop; exit 0; }
test -d /sys/fs/cgroup || { stop; exit 0; }
/bin/cgroups-mount
cgconfigparser -l /etc/cgconfig.conf
end script
post-stop script
if [ -x /bin/cgroups-umount ]
then
/bin/cgroups-umount
fi
end script
新建 /etc/cgconfig.conf文件# Since systemd is working well, this section may not be necessary.
# Uncomment if you need it
#
# mount {
# cpuacct = /cgroup/cpuacct;
# memory = /cgroup/memory;
# devices = /cgroup/devices;
# freezer = /cgroup/freezer;
# net_cls = /cgroup/net_cls;
# blkio = /cgroup/blkio;
# cpuset = /cgroup/cpuset;
# cpu = /cgroup/cpu;
# }
group limitcpu{
cpu {
cpu.shares = 400;
}
}
group limitmem{
memory {
memory.limit_in_bytes = 512m;
}
}
group limitio{
blkio {
blkio.throttle.read_bps_device = "252:0 2097152";
}
}
group browsers {
cpu {
# Set the relative share of CPU resources equal to 25%
cpu.shares = "256";
}
memory {
# Allocate at most 512M of memory to tasks
memory.limit_in_bytes = "512m";
# Apply a soft limit of 512 MB to tasks
memory.soft_limit_in_bytes = "384m";
}
}
group media-players {
cpu {
# Set the relative share of CPU resources equal to 25%
cpu.shares = "256";
}
memory {
# Allocate at most 256M of memory to tasks
memory.limit_in_bytes = "256m";
# Apply a soft limit of 196 MB to tasks
memory.soft_limit_in_bytes = "128m";
}
}
应用配置cgconfigparser -l /etc/cgconfig.conf
启动cgconfigsudo service cgconfig restart